

The TechBeat: VSYS Host Launches VSYS Name - an ICANN-Accredited Domain Registrar (11/22/2025)
How are you, hacker? 🪐Want to know what's trending right now?: The Techbeat by HackerNoon has got you covered with fresh content from our trending stories of the day! Set email preference here. ## Building a RAG System That Runs Completely Offline  By @teedon [ 30 Min read ] Build a private, offline RAG with Ollama + FAISS. Ingest docs, chunk, embed, and cite answers—no APIs, no cloud, full control over sensitive data. Read More.
By @teedon [ 30 Min read ] Build a private, offline RAG with Ollama + FAISS. Ingest docs, chunk, embed, and cite answers—no APIs, no cloud, full control over sensitive data. Read More.
I Built a Python Script to Make 10,000 Laws Understandable 
By @knightbat2040 [ 6 Min read ] Built an AI tool that scrapes, cleans, and summarizes Texas bills to make government legislation readable and transparent for everyone. Read More.
From Tasks to Thinking Systems: Why Automation Starts in the Mind, Not the Machine 
By @hacker53037367 [ 18 Min read ] A reflection on why true automation starts with human thinking, not technology. Systems only work as clearly as the minds that design them. Read More.
12 Best Web Scraping APIs in 2025 
By @oxylabs [ 11 Min read ] Discover the 12 best web scraping APIs of 2025, comparing performance, pricing, features, & success rates to help teams scale reliable data extraction. Read More.
AIOZ AI: The People-Powered AI Stack on AIOZ Network 
By @aioznetwork [ 5 Min read ] AIOZ AI is the intelligence layer of the AIOZ Network, connecting a global community through a peer-to-peer compute economy. Learn more here! Read More.
A Developer’s Guide to Building Next-Gen Smart Wallets with ERC-4337 — Part 1: The EntryPoint 
By @hacker39947670 [ 14 Min read ] Hands-on ERC-4337 guide: deploy EntryPoint, build a minimal smart account, fund deposits, and send your first UserOperation with Foundry and TypeScript Read More.
Humanity Protocol Integrates Open Finance into Human ID 
By @kashvipandey [ 2 Min read ] Humanity Protocol partners with Mastercard to integrate open finance into Human ID, enabling secure, privacy-first access to loans, credit, and Web3 finance. Read More.
Why DynamoDB Costs Explode 
By @scylladb [ 5 Min read ] Discover how DynamoDB’s pricing quirks—rounding, replication, caching, and global tables—can skyrocket costs, and how ScyllaDB offers predictable pricing. Read More.
Can 25 Superhumans Run a $100M Freight Operation? T3RA’s AI Visionary Mukesh Kumar Thinks So 
By @stevebeyatte [ 8 Min read ] T3RA Logistics is redefining freight with AI agents—running a $100M operation with just 25 “superhumans.” Read More.
The Fork Reshaping MCP Testing: How a 24-Year-Old CTO Is Taking On One of AI’s Biggest Players 
By @stevebeyatte [ 4 Min read ] A 24-year-old developer built MCPJam, an open-source rival that outpaced Anthropic’s Inspector—and may redefine how AI agents are tested. Read More.
VSYS Host Launches VSYS Name - an ICANN-Accredited Domain Registrar 
By @hacker38388747 [ 2 Min read ] VSYS Host launches VSYS Name, an ICANN-accredited registrar offering direct domain control, transparent pricing, crypto payments, and 24/7 expert support. Read More.
The Paycheck Era is Dying 
By @benoitmalige [ 7 Min read ] The paycheck era is ending. Learn why wages are collapsing, leverage is rising, and how to build a life where you're paid for impact, not time. Read More.
DevOps Isn't a Tool, It's a Chain Reaction 
By @amanila [ 70 Min read ] A beginner's introduction to DevOps foundations. Connect the dots between Git, CI/CD, Docker, and Kubernetes to understand the modern development rocess. Read More.
What Happens When Telegram's 1 Billion Users Get Access to Ethical AI? AlphaTON Has a Plan 
By @ishanpandey [ 5 Min read ] AlphaTON partners with SingularityNET to deploy hydroelectric-powered GPUs for Telegram's Cocoon AI network in Sweden. Read More.
Can ChatGPT Outperform the Market? Week 14 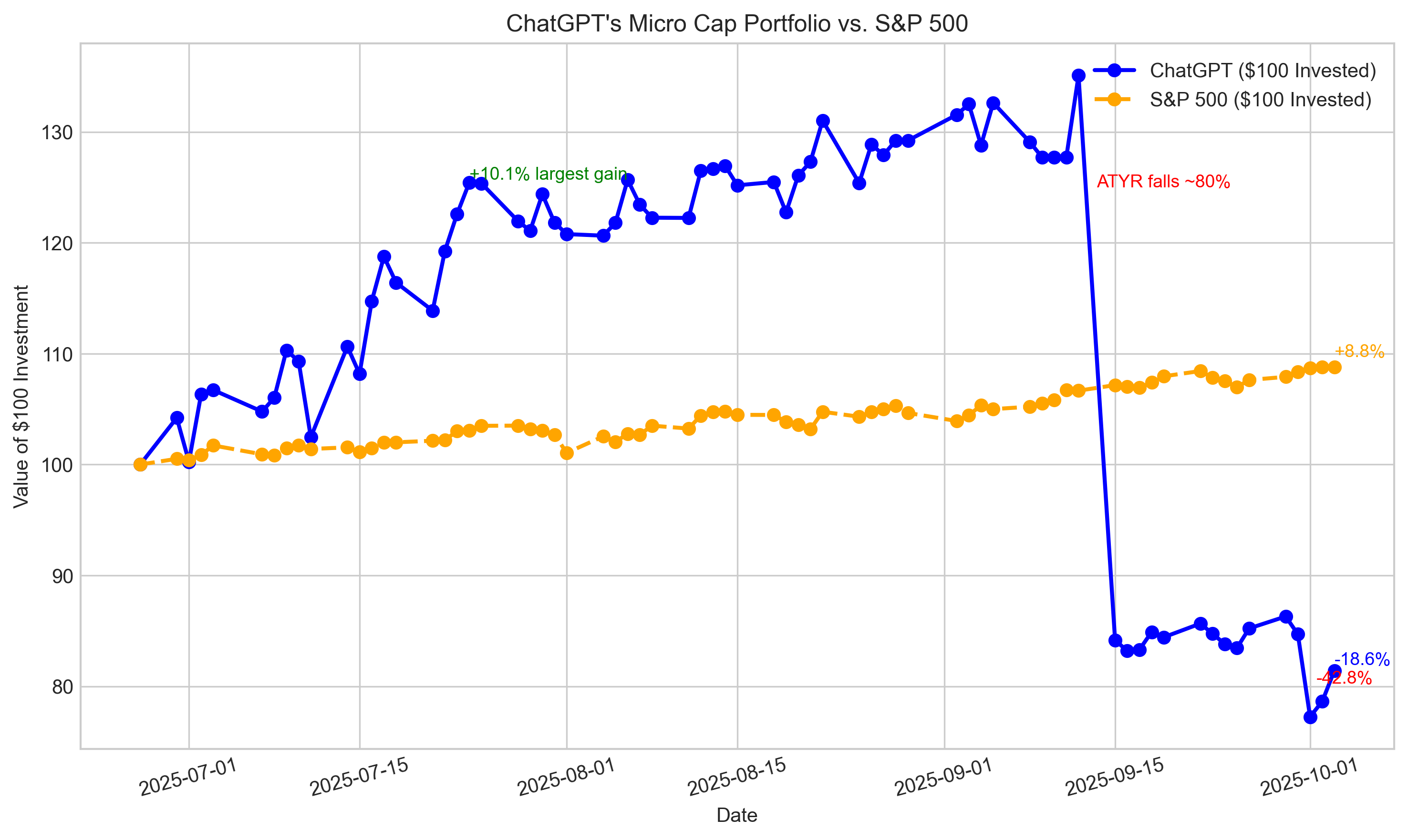
By @nathanbsmith729 [ 4 Min read ] FBIO's key trial denied… Read More.
Elaborate Hoaxes in the Age of AI 
By @jacoblandry [ 4 Min read ] We know there's a lot of unethical ways to use AI but at what point are we not even going to know AI was used? Read More.
Tf2cdk – Convert Terraform to AWS CDK (Not Cdktf) 
By @jtaylortech [ 3 Min read ] How to convert terraform to cdk Read More.
Researchers Develop AI to Spot Early Signs of Cerebral Palsy in Infants 
By @yuliabusygina [ 10 Min read ] Researchers at Saint Petersburg State Pediatric Medical University developed an AI solution for assessing infant brain development from MRI scans. The solution Read More.
Why 25% of Bitcoin Supply Faces Quantum Threat and What QANplatform Is Doing About It 
By @ishanpandey [ 5 Min read ] QANplatform's QAN XLINK passes Hacken security audit, offering quantum-resistant protection for 25% of Bitcoin supply vulnerable to future attacks. Read More.
Can ChatGPT Outperform the Market? Week 16 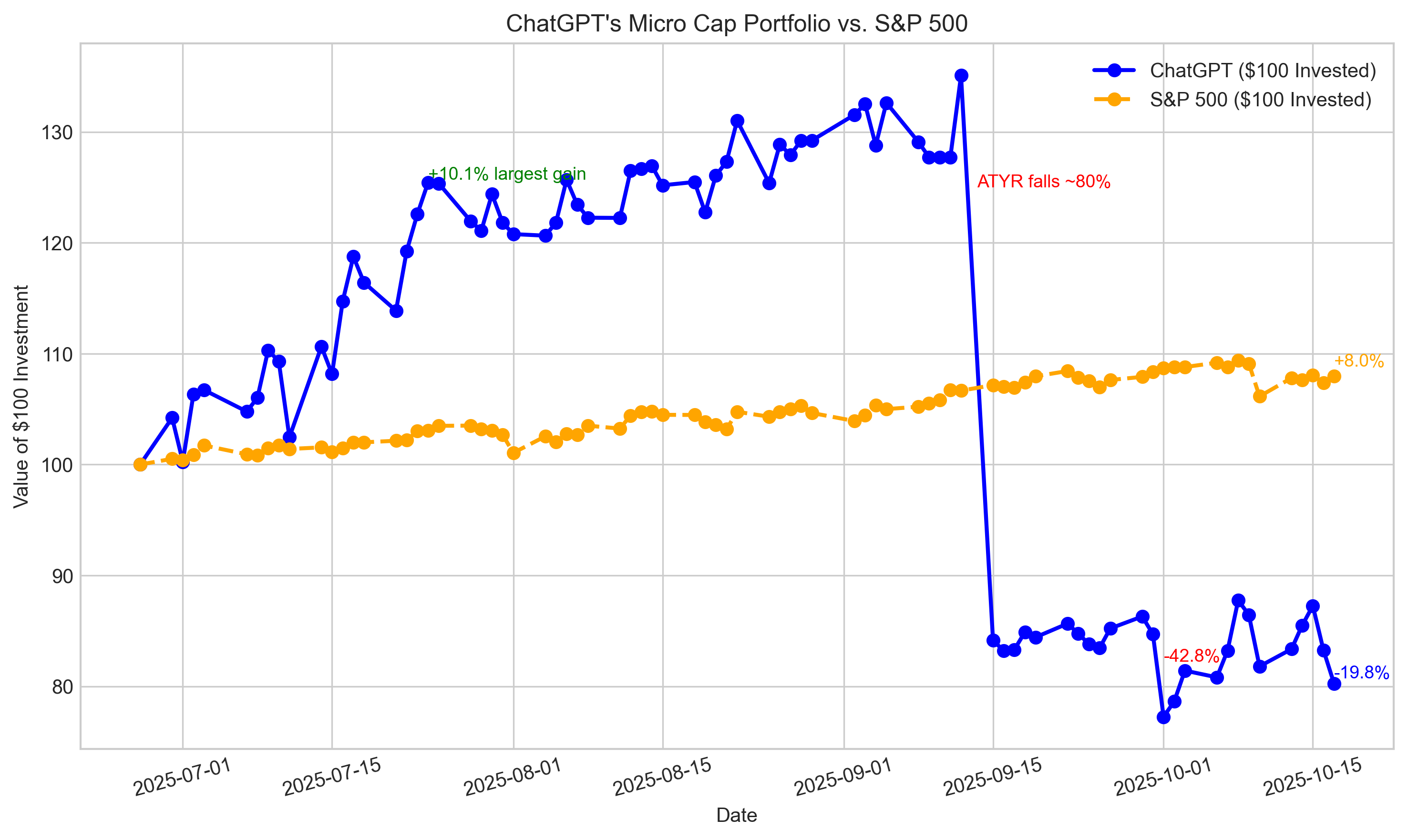
By @nathanbsmith729 [ 6 Min read ] Another losing streak.. Read More. 🧑💻 What happened in your world this week? It's been said that writing can help consolidate technical knowledge, establish credibility, and contribute to emerging community standards. Feeling stuck? We got you covered ⬇️⬇️⬇️ ANSWER THESE GREATEST INTERVIEW QUESTIONS OF ALL TIME We hope you enjoy this worth of free reading material. Feel free to forward this email to a nerdy friend who'll love you for it. See you on Planet Internet! With love, The HackerNoon Team ✌️ 


You May Also Like

The 2022 Playbook Says Bitcoin Fails Here. On-Chain Data Says This Cycle Is Different

Covéa Chooses Shift Technology as Strategic Partner for Fraud and Risk Management




