

Evolving UX Research Methods for AI Agents in Enterprise Collaboration

\ The shift happened faster than anyone predicted. One day, AI was autocompleting our sentences. The next, it was joining our meetings, summarizing our conversations, and drafting follow-up messages on our behalf. Now it is making decisions.
I have spent years researching how teams collaborate through intelligent platforms, and what I am witnessing today represents the most significant transformation in workplace dynamics since the introduction of email. AI agents are no longer tools we use. They are participants we work alongside.
This distinction matters enormously for UX researchers. The methods we developed to evaluate software features simply do not apply when that software starts behaving like a team member.
The Fundamental Shift: From Feature to Participant
Traditional UX research asks questions like: Is this feature discoverable? Is the interaction intuitive? Does it reduce friction in the workflow?
These questions assume the AI is passive, waiting for user input before responding. But AI agents operate differently. They observe, interpret, decide, and act. According to MIT Sloan Management Review and Boston Consulting Group's 2025 research, 35% of organizations have already begun using agentic AI, with another 44% planning to adopt it soon. Yet 47% indicate they have no strategy for what they are going to do with AI. This gap between adoption and understanding is precisely where UX research must step in.
When an AI agent joins a collaboration platform, it changes the social dynamics of the team. It affects who speaks, when they speak, and what they feel comfortable saying. Evaluating these shifts requires methods that go far beyond usability testing.
\ 
Leading AI Evaluation for Enterprise Collaboration Platforms
In my work leading UX research for intelligent collaboration platforms, I have developed evaluation frameworks specifically designed for AI agents operating in enterprise environments. This work sits at the intersection of product strategy, AI development, and human factors research.
AI evaluation in this context is fundamentally different from traditional model benchmarking. When an AI agent operates within a collaboration platform, we cannot simply measure accuracy or response quality in isolation. We must evaluate how the agent performs within the complex social and operational dynamics of real teams.
I approach AI evals for enterprise collaboration through three interconnected layers. The first layer examines functional performance: does the agent correctly identify action items, summarize discussions accurately, and surface relevant information at appropriate moments? The second layer assesses integration quality: how seamlessly does the agent operate within existing workflows without creating friction or requiring behavioral changes from users? The third layer, and the one most often overlooked, evaluates systemic impact: how does the agent's presence affect team dynamics, decision quality, and collaborative effectiveness over time?
Harvard Business Review research from May 2025 describes AI agents as "digital teammates" representing an emerging category of talent. This framing demands that we evaluate AI agents not just on task completion, but on how well they function as team participants. My evaluation protocols incorporate behavioral observation, longitudinal tracking, and outcome analysis that traditional AI benchmarks entirely miss.
The organizations achieving the strongest results are those that embed UX research directly into their AI evaluation cycles, using human-centered metrics alongside technical performance measures.
\
Building Hyper-Personalized AI Agents Through Strategic UX Research
The next frontier for enterprise collaboration platforms is hyper-personalized AI agents that adapt to individual users, team cultures, and organizational contexts. This is where UX research becomes not just evaluative but generative, directly shaping how these agents are designed and deployed.
I have been leading research initiatives that inform the strategic development of personalized AI agents for collaboration platforms. This work involves understanding the specific patterns of how different user types interact with AI, how team communication styles vary across functions and geographies, and how organizational culture influences what users expect from AI assistance.
McKinsey's November 2025 research on AI partnerships notes that realizing AI's potential requires redesigning workflows so people, agents, and robots work together effectively. From a product strategy perspective, this means AI agents cannot be one-size-fits-all. They must adapt their communication style, intervention frequency, and level of autonomy based on user preferences and contextual factors.
My research has identified several personalization dimensions that matter most in enterprise collaboration contexts. Communication style matching ensures the agent mirrors how users naturally express themselves, whether formal or casual, detailed or concise. Intervention timing calibration learns when individual users prefer proactive assistance versus when they want to work uninterrupted. Trust threshold adjustment recognizes that different users have different comfort levels with AI autonomy and calibrates accordingly.
The strategic implications are significant. Product teams building AI agents for collaboration platforms need continuous UX research input to understand how personalization features perform across diverse user populations. Without this research foundation, personalization efforts risk creating agents that feel intrusive to some users while seeming unhelpful to others.
A Framework for Evaluating AI Agents in Collaborative Settings
Through extensive field research with cross-functional teams adopting AI agents in their collaboration workflows, I have developed an evaluation framework built around four dimensions that traditional methods overlook.
- Presence Impact examines how the AI agent's presence changes team behavior, independent of its functional contributions. I have observed teams become measurably more formal when they know an AI is documenting their conversations. Sidebar discussions decrease. Exploratory thinking gets replaced by safer contributions.
- Agency Boundaries addresses where the AI agent's autonomy should begin and end, and how teams negotiate these boundaries. The World Economic Forum's 2025 guidance on AI agents emphasizes that governance must promote transparency through continuous monitoring. In my research, I have found that stated preferences for AI autonomy rarely match revealed preferences. Teams often say they want AI agents to take more initiative, but resist when agents actually do so.
- Trust Calibration focuses on how teams develop appropriate trust, avoiding both over-reliance and under-utilization. An AI agent that makes one significant error can destroy months of trust-building, while an agent that performs perfectly can create dangerous complacency.
- Collaborative Integration examines how the AI agent affects team dynamics, information flow, and collective intelligence. Does the AI agent help the team make better decisions, or create an illusion of thoroughness masking shallow thinking?
Case Study: Reconfiguring AI Agent Scope
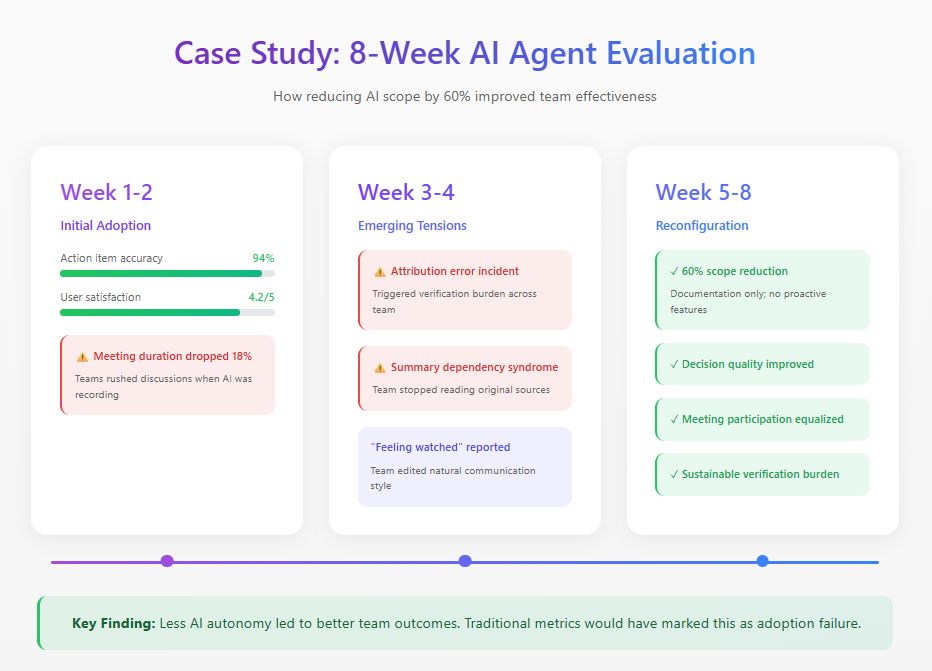
I recently conducted an eight-week study with a distributed product team implementing an AI agent across their collaboration platform. The agent was designed to attend meetings, generate summaries, track decisions, and proactively surface relevant information.
Initial metrics looked excellent: 94% action item accuracy, 4.2 out of 5 satisfaction ratings. But behavioral observation revealed problems invisible to dashboards. Meeting duration dropped 18% as team members rushed discussions, conscious that every word was being captured. By week three, an attribution error triggered a verification burden that consumed more time than the documentation it replaced. Team members also developed what I call "summary dependency syndrome," relying exclusively on AI summaries and missing crucial context.
Based on these findings, the team reconfigured the AI agent, reducing its functional scope by 60%. They removed proactive features while retaining documentation tasks where accuracy was high. Traditional adoption metrics would mark this as failure. But team effectiveness measures told a different story: decision quality improved, meeting participation became more equitable, and the verification burden dropped to sustainable levels.
The most significant finding emerged from interviews. Multiple team members described feeling "watched" during full-autonomy phase. This chilling effect on authentic communication never appeared in any dashboard metric.
\ 
\
Practical Evaluation Methods
Based on this research and similar studies, I recommend the following methods for evaluating AI agents in collaborative settings.
- Longitudinal Observation requires minimum six-week observation periods with baseline establishment before AI agent introduction. Single-session usability tests reveal almost nothing useful about collaborative AI dynamics.
- Communication Pattern Analysis involves quantitative tracking of who speaks, how often, and in what contexts across pre-deployment, early deployment, and mature deployment phases.
- Trust Calibration Assessment regularly measures how team members' confidence in AI capabilities compares to actual AI performance.
- Decision Quality Audits provide retrospective analysis of decisions made with AI agent involvement, tracking outcomes and identifying where AI contribution helped or hindered.
The Path Forward
AI agents will become ubiquitous in enterprise collaboration. The research question is not whether organizations will adopt them, but how they will integrate them effectively.
UX researchers have a critical role in shaping this integration. We possess the methods to understand human behavior and the frameworks to evaluate experience quality. The organizations that get this right will build collaboration systems where humans and AI agents genuinely complement each other. Those who treat AI agents as just another feature will discover their teams work less effectively than before the technology arrived.
\
You May Also Like

South Korea Launches Innovative Stablecoin Initiative

Trump Cancels Tech, AI Trade Negotiations With The UK
