

The Seven Pillars of a Production-Grade Agent Architecture
:::info This is the third article in a five-part series on agentic AI in the enterprise. In Part 2, we outlined the “crawl, walk, run, fly” maturity phases of AI agent adoption. Now we shift from concepts to construction: what underlying architecture do you need to get an AI agent beyond the demo stage and into reliable production? Here we introduce the seven core pillars of an enterprise-ready agent architecture, with practical design insights for each.
:::
\ Under the hood, successful agentic AI systems tend to share a common architectural DNA. In my work, I often break this down into seven pillars: critical components that must work in harmony to move an AI agent from a nifty proof-of-concept to a reliable, production-grade solution. These pillars form a kind of layered stack of capabilities, from how an agent perceives input at the bottom up to how it is governed at the top. You can think of it as a vertical slice through an AI agent’s “brain and body.” If any layer is weak, the whole agent can stumble. Getting all seven in place is key to scaling an agent beyond toy problems. Let’s briefly explore each pillar and some design checkpoints and lessons learned for each.
\ 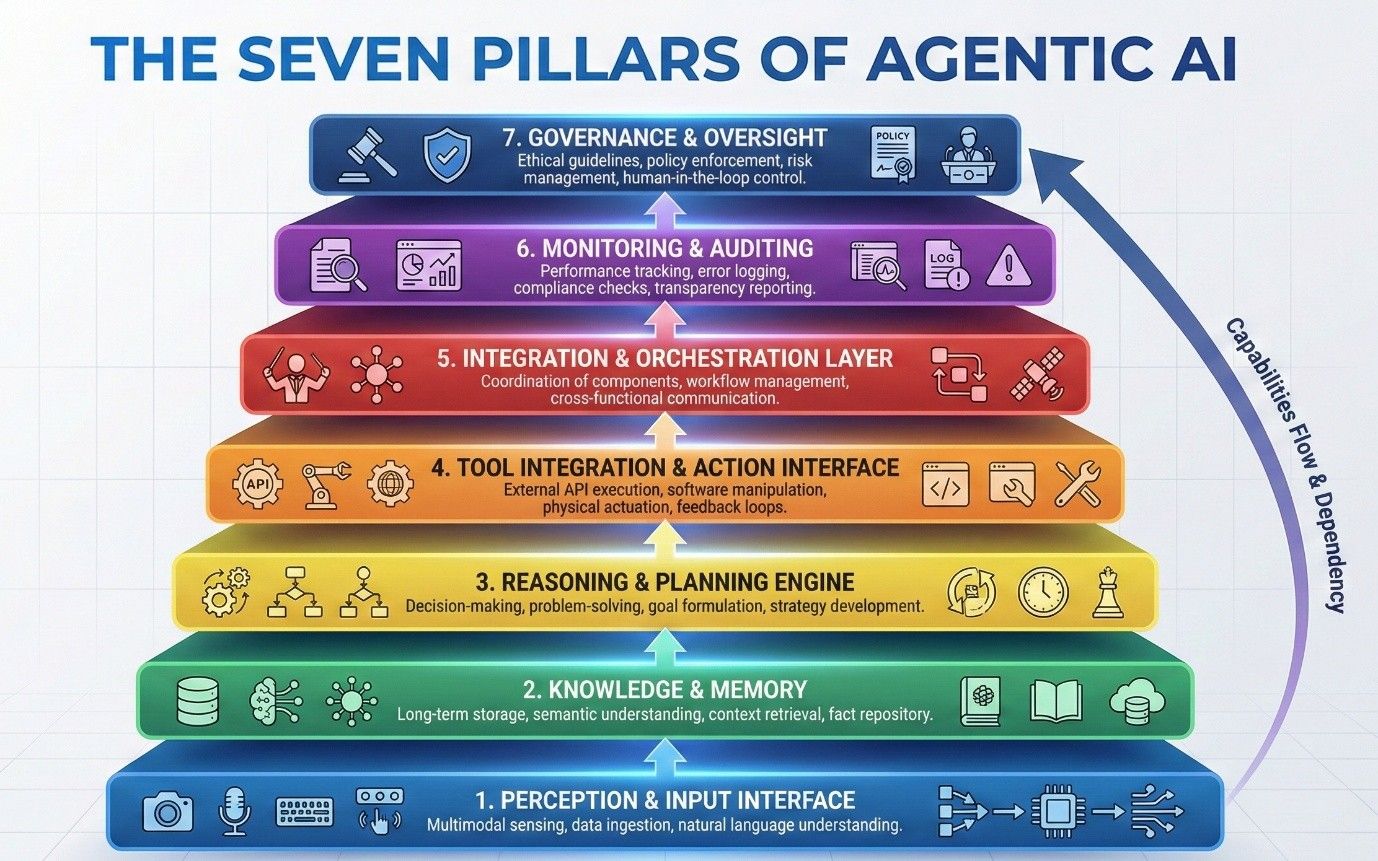
\ 1. Perception & Input Interface. Every agent needs a way to perceive its environment and understand instructions. This pillar covers how the agent knows when to act and with what data or command. Inputs can come in various forms: a direct user prompt, an event trigger from another system, a sensor reading, a scheduled job, etc. In enterprise scenarios, agents often run event-driven (e.g. an agent wakes up when a new support ticket is created, or when inventory drops below a threshold) rather than sitting idle waiting for a person to type a request. Designing clear input channels and triggers is crucial so the agent knows when to spring into action and with what context.
· Design checks: Define what events or signals invoke the agent. If natural language input is used (for example, a chat interface or email instructions), ensure you have robust NLP parsing so the agent correctly interprets user intent. We learned the hard way that strict input validation is key - real-world data can be messy (typos, ambiguous phrases, malformed records) and can make an agent misinterpret the task, going off track. We implemented pre-processing to clean and normalise inputs, and fail-safe checks: if the input doesn’t make sense or is out of bounds, the agent should ask for clarification or log an error rather than blundering ahead on potentially wrong info. Essentially, “garbage in = garbage out”, squared - because an autonomous agent acting on a bad input can cause a lot of mischief before anyone notices.
\ 2. Knowledge & Memory (Context Store). Unlike a stateless script, an intelligent agent maintains memory - both short-term context (what it’s working on right now) and long-term knowledge (facts learned or provided). This pillar is the agent’s knowledge base and working memory. It can include enterprise data sources, document repositories, a history of previous interactions, and specialised memory stores (like a vector database of embeddings for semantic search). Memory gives the agent situational awareness beyond the immediate input. For example, an agent troubleshooting IT incidents might recall how it solved a similar issue last week; a sales agent might remember a client’s preferences from prior chats.
· Design checks: Ensure the agent is getting the right contextual data at each step. Decide what it should remember versus what it should ignore or forget. Too little memory and the agent will be short-sighted or repetitive; too much and it may get confused or even expose sensitive info. We learned to carefully scope an agent’s memory window, for instance, limit it to the last N interactions or to specific data relevant to the current task. We also implemented data governance around memory: ensure the knowledge store is up-to-date and accurate. If you feed an agent stale or incorrect info, it will make bad decisions: a form of “memory poisoning” that can happen inadvertently if the knowledge base isn’t maintained. The art is injecting just enough relevant context into the agent’s working memory so it has what it needs and nothing more. Often this involves retrieval techniques to fetch pertinent knowledge on the fly (retrieval-augmented generation, semantic search, etc.). Good agents are like good detectives: they recall the right facts at the right time to solve the case.
\ 3. Reasoning & Planning Engine. This is the agent’s problem-solving core, the “AI brain” that analyses inputs and charts a course of action. Under the hood, this usually involves one or more AI models (often a large language model, LLM) plus some logic or algorithms to guide them. The reasoning engine takes the user’s request or the current situation plus context from memory and decides what to do next. Modern agents lean heavily on LLMs for this component, since LLMs are surprisingly proficient at chain-of-thought reasoning when properly prompted. However, LLMs on their own have limitations: they can lose coherence on lengthy problems or suggest illogical steps. In our experience, the best results came from hybrid approaches: using an LLM for its flexibility and knowledge, but complementing it with simple rules or search algorithms for structure and sanity-checks. For instance, we had an agent that would generate possible next steps with GPT-4, but then run those through a rules engine to filter out any obviously invalid or risky actions before execution.
Planning is a crucial part of this pillar: the agent needs a way to break high-level goals into subtasks and adjust its approach on the fly. We built a “re-plan on failure” ability: if Plan A doesn’t achieve the goal or hits an error, the agent can try Plan B or escalate to a human, rather than getting stuck or looping endlessly.
· Design checks: Does your agent have a way to decompose complex tasks and re-plan if it hits an obstacle? If you’re using an LLM for reasoning, have you implemented techniques like the ReAct pattern (interleaving reasoning and action) or other prompt strategies to improve step-by-step planning? (The ReAct approach - reasoning in natural language, then calling an action, then reasoning again - can help the LLM stay on track). What happens if the agent’s plan fails unexpectedly - can it backtrack or try an alternative path? It’s wise to encode some guardrails in the reasoning process, since an LLM might propose an action that is nonsensical or unsafe. We found that giving the agent a “mental checklist” (some hard rules to always obey, e.g. don’t delete data without confirmation) dramatically reduced crazy plans. In sum, this pillar is about making the agent smart and strategic, not just reactive, but also keeping its reasoning bounded by logic and business rules.
\ 4. Tool Integration & Action Interface. Thought without action only gets you so far. Once an agent decides on a step, it needs the ability to execute actions in the real world. This pillar is about connecting the agent to external tools, systems, and APIs, effectively giving it “hands and feet.” For example, if an agent’s task is to handle employee onboarding, it might need to: create accounts in an HR system via API, send a welcome email via an email service, and schedule training sessions via a calendar API. The action interface provides these hooks. Modern agent frameworks often come with collections of tool plug-ins (for web browsing, database queries, sending emails, etc.) to speed this up.
· Design checks: Explicitly decide what actions you will allow the agent to take, and how you will control them. We treated external tools as first-class elements in our design, meaning we defined exactly which APIs or commands the agent could call, with what parameters, and we sandboxed its execution environment. An autonomous agent that can run code or spend money (e.g. auto-ordering supplies) must be tightly governed! In practice, we maintained a whitelist of permitted actions for each agent and built monitoring around tool usage. If the agent tried to do something outside its toolbox, it was blocked and logged for review. Also, consider how the agent handles tool failures: e.g. if an API call times out or returns an error, the agent should catch that and respond appropriately (maybe retry with backoff, or flag a human). Too many early agent prototypes blithely assumed every action would succeed and just moved on, only to create inconsistencies or incomplete work when something went wrong. Build in error handling and timeouts for any tool calls. Lastly, keep security in mind: use proper authentication for APIs and ensure the agent doesn’t have broader access than necessary. The principle of least privilege applies to AI agents too.
\ 5. Integration & Orchestration Layer. In a real enterprise deployment, an agent doesn’t live in a vacuum. This pillar covers the “glue” that connects the agent into larger workflows and coordinates multiple agents if you have more than one. On one hand, integration means managing how the agent plugs into your existing IT landscape: scheduling the agent (e.g. ensure an agent runs every night at 3am to check for anomalies), feeding it the data it needs from various systems (CRM, ERP, databases), and routing its outputs to the right place (for example, feeding the agent’s result into a ticketing system so work is actually applied). On the other hand, orchestration comes into play when you deploy multiple agents or micro-agents. Rather than one monolithic AI doing everything, many designs use a team of specialised agents that collaborate (much like microservices in software). For example, you might have a “data extraction agent” and a “report writing agent” that work together, with a supervising agent coordinating them. We implemented this “team of agents” approach at a large insurance firm: instead of one giant claims-processing bot, we built five focused agents (a data extractor, a policy analyser, a fraud checker, a payout calculator, and a communication bot) that handed off tasks to each other. A central orchestrator service assigned sub-tasks to the right agent via a queue, then aggregated their outputs at the end. The result was easier development and improved reliability: if one component failed or underperformed, it was easier to pinpoint and fix than if a single all-in-one agent went awry.
· Design checks: Think through how the agent (or agents) will plug into your broader processes. Are there clear APIs or messaging pipelines for it to receive triggers and to output results? If multiple agents are deployed, how will they communicate and avoid stepping on each other’s toes? We found that treating each agent as a microservice (with a defined input/output contract and its own API endpoint or message queue) is a good practice. It makes monitoring and scaling easier too. Also consider transactionality: if Agent A’s output is input for Agent B, how do you handle partial failures or retries? This layer may not sound glamorous, but without solid integration, an AI agent remains a fancy toy disconnected from real business workflows.
Emerging standards are worth keeping an eye on here. For instance, OpenAI introduced a function calling specification that allows LLMs to invoke external functions in a controlled way (essentially a standard JSON-based API call mechanism) in 2023, and in multi-agent orchestration we’re seeing efforts like the new Agent-to-Agent (A2A) protocol - an open standard launched by Google in 2025 with support from dozens of partners - which aims to let AI agents from different vendors talk to each other seamlessly (https://cloud.google.com/blog/products/ai-machine-learning/agent2agent-protocol-is-getting-an-upgrade). The takeaway: integration and orchestration are becoming easier with evolving frameworks, but it still requires architectural forethought on your part to use them effectively.
\ 6. Monitoring & Auditing. Last, but absolutely not least, is continuous monitoring of the agent in production. A production agentic AI system requires ongoing observability, just like any mission-critical software (if not more so). This pillar includes mechanisms to track the agent’s behaviour, evaluate its decisions, and record what it’s doing for later analysis. In practical terms, that means setting up extensive logging for every significant action or decision the agent makes, and building dashboards and alerts to monitor those logs in real time. For example, in one deployment we set an alert if an agent started taking an unusually long sequence of steps or repeated a step too many times (a possible sign of a loop or confusion).
· Design checks: Do you have a way to audit every decision or action the agent takes? Can you detect anomalies in its behaviour, such as a sudden burst of activity, an output that deviates from expected parameters, or a drop in success rate? It’s much easier to build trust (with both users and regulators) when you can show a complete audit trail of the agent’s actions. In our case, establishing robust monitoring (we jokingly called it AgentOps, by analogy to DevOps) gave stakeholders confidence. For instance, our compliance team became a lot more comfortable with the AI when they saw we could easily pull up logs of every action and even replay the agent’s decision process step by step. As a result, they green-lit expansion of the agent to more use cases.
Furthermore, monitoring isn’t just for catching bad behaviour; it’s for improving the agent. We set up dashboards for key metrics (more on metrics in Part 5) like accuracy, task completion rate, average response time, etc., and tracked these over time. When we noticed a dip or anomaly, it prompted an investigation - maybe the model needed tuning or a knowledge base update. Gartner’s research found that organisations who perform regular AI system assessments and audits are over three times more likely to achieve high business value from their AI initiatives than those that “set and forget” (https://www.gartner.com/en/newsroom/press-releases/2025-11-04-gartner-survey-finds-regular-ai-system-assessments-triple-the-likelihood-of-high-genai-value). In short, if you’re going to give an AI agent some autonomy, you need to watch it like a hawk - especially in the early stages - and create feedback loops to continually learn and correct course.
\ 7. Governance & Oversight. Even with good monitoring, you need proactive governance to keep an autonomous agent on the rails. This top pillar is about defining policies, ethical guidelines, and guardrails so the AI operates within safe bounds, and having human oversight over the whole endeavour. For example, you might require an agent to get human sign-off for high-impact decisions (like approving a large payment), or you might limit an agent to read-only access in its early deployments until it proves trustworthy. We embedded such rules from day one in our projects. We also set up clear escalation paths: e.g. if the agent is unsure what to do or detects an error, it should automatically hand off to a human operator or gracefully shut down and alert the on-call team.
Additionally, we established an internal AI oversight committee (or at least involved our AI Center of Excellence) to ensure cross-functional input into how agents are deployed and managed. This included IT, business stakeholders, compliance, and security teams - everyone had a seat at the table to raise concerns and set guardrails. Gartner and others have cautioned that letting AI agents proliferate without proper control can lead to “rogue AI” incidents or simply a lot of wasted effort on bots that nobody monitors or trusts. We took that to heart: no agent went live without a governance review and an owner accountable for its outcomes.
· Design checks: Are there guardrails to prevent unsafe actions (for instance, spending over a certain limit or accessing sensitive data)? Have you defined who is accountable if the agent makes a mistake or causes an incident? Is there a kill switch or rollback plan if things go wrong? It’s crucial to plan how you will handle the situation if (when) the agent does something unexpected. In our deployments, just having a well-defined fallback procedure (like “if the agent’s confidence is low or it encounters an error, it will ping a human for review and await confirmation”) gave management more confidence to deploy the agent, because they knew it wouldn’t go off the rails silently. Good governance might sound bureaucratic, but done right it’s actually an enabler: interestingly, Gartner found that companies with robust AI governance not only had fewer incidents, they also achieved higher value outcomes from AI. In fact, the OWASP GenAI Security Project now ranks prompt injection attacks as the #1 most critical vulnerability for LLM-based applications - underscoring how seriously we need to take this risk (https://genai.owasp.org/llmrisk/llm01-prompt-injection/). In our experience, establishing strong governance processes actually accelerated adoption, for example, our compliance team became much more supportive once they saw we had proper oversight and fail-safes in place.
\ By ensuring these seven pillars are solid, you create an environment where AI agents can truly thrive in enterprise settings. Not coincidentally, these pillars align closely with what major tech providers are building into their AI platforms. The big cloud vendors - AWS, Microsoft, Google, IBM, etc. - have all rolled out agent development toolkits covering many of these layers out-of-the-box. For instance, Google’s Vertex AI platform now includes an Agent Builder with connectors and an agent runtime; AWS’s Bedrock service offers managed agent capabilities with an orchestration layer and tool integrations; Microsoft’s new Copilot Studio provides a platform for enterprises to customise and launch AI agents easily (https://www.microsoft.com/en-us/microsoft-365-copilot/microsoft-copilot-studio); IBM’s watsonx Orchestrate helps automate business workflows by orchestrating multiple AI and RPA components, essentially IBM’s take on agentic AI for enterprise processes (https://www.ibm.com/products/watsonx-orchestrate). The takeaway is that the technology stack is maturing fast to support agentic AI. It’s on us as architects and leaders to assemble these building blocks into solutions that deliver real business outcomes (and to mind those pesky details like data quality, security, and user adoption - more on those soon).
\ Having laid out the architecture foundations, you might be wondering: what does this look like in practice? In the next part, we’ll shift gears from components to patterns. We’ll discuss what kinds of agent deployments are actually yielding ROI in the field today, and the common pitfalls that cause others to fail. Essentially: how do you apply these pillars smartly to solve real business problems? Let’s talk.
\
You May Also Like

Unleashing A New Era Of Seller Empowerment

Foreigner’s Lou Gramm Revisits The Band’s Classic ‘4’ Album, Now Reissued
