

Solidne matowanie z wykorzystaniem maski: zarządzanie zaszumionymi danymi wejściowymi i wszechstronnością obiektów
Spis Odnośników
Abstrakt i 1. Wprowadzenie
-
Prace Powiązane
-
MaGGIe
3.1. Efektywne Maskowane Prowadzone Matowanie Instancji
3.2. Czasowa Spójność Cechy-Matte
-
Zbiory Danych do Matowania Instancji
4.1. Matowanie Instancji Obrazu i 4.2. Matowanie Instancji Wideo
-
Eksperymenty
5.1. Wstępne trenowanie na danych obrazowych
5.2. Trenowanie na danych wideo
-
Dyskusja i Bibliografia
\ Materiały Uzupełniające
-
Szczegóły Architektury
-
Matowanie obrazu
8.1. Generowanie i przygotowanie zbioru danych
8.2. Szczegóły trenowania
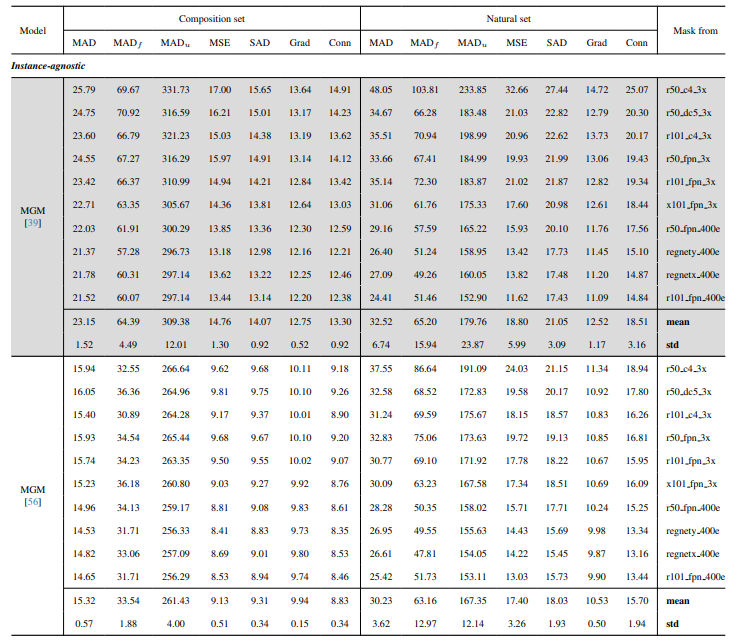
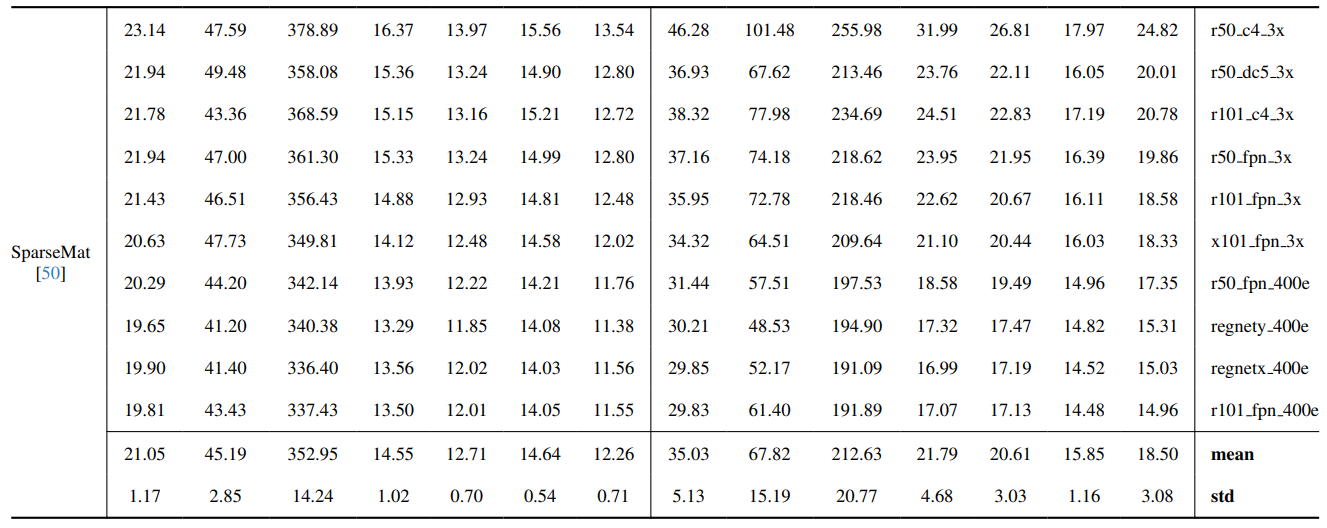
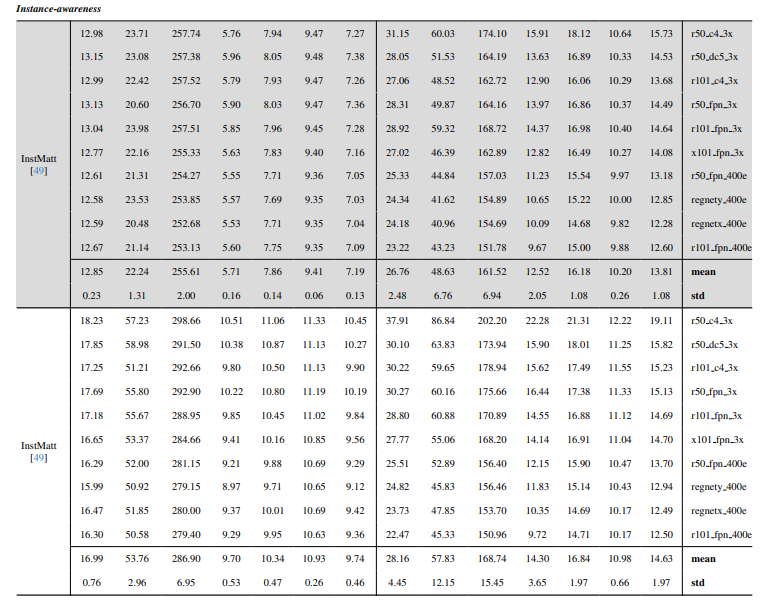
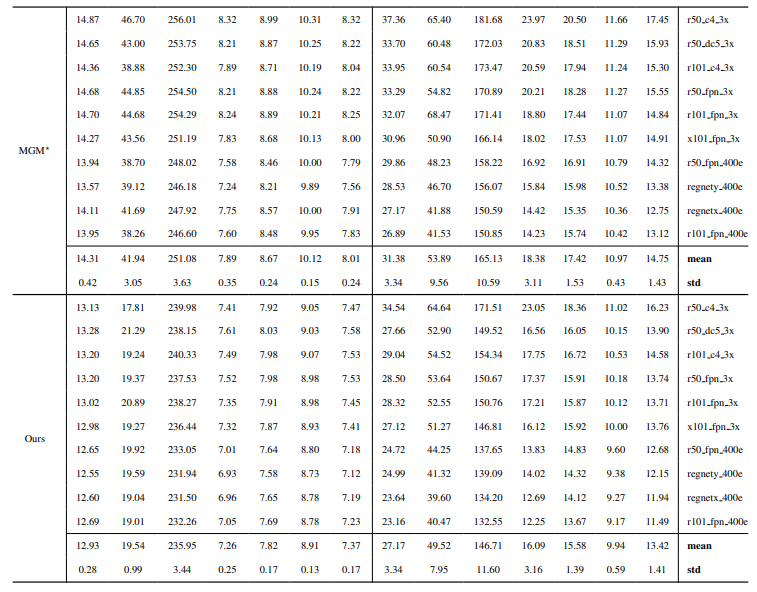
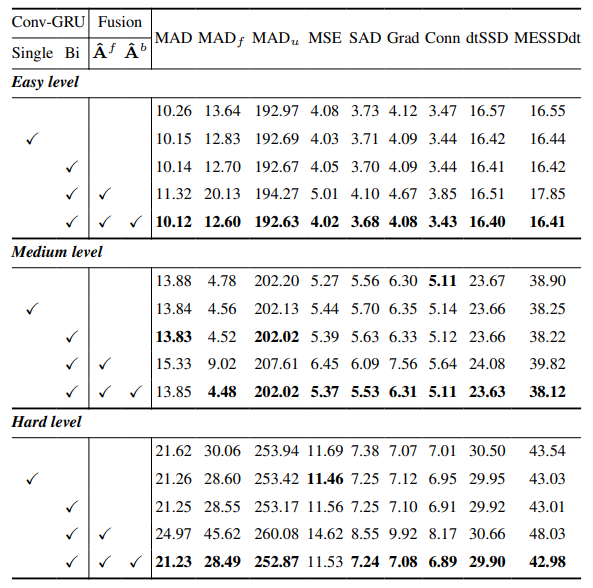
8.3. Szczegóły ilościowe
8.4. Więcej wyników jakościowych na obrazach naturalnych
-
Matowanie wideo
9.1. Generowanie zbioru danych
9.2. Szczegóły trenowania
9.3. Szczegóły ilościowe
9.4. Więcej wyników jakościowych
8.4. Więcej wyników jakościowych na obrazach naturalnych
Rys. 13 przedstawia wydajność naszego modelu w trudnych scenariuszach, szczególnie w dokładnym renderowaniu obszarów włosów. Nasze ramy konsekwentnie przewyższają MGM⋆ w zachowywaniu szczegółów, zwłaszcza w złożonych interakcjach instancji. W porównaniu z InstMatt, nasz model wykazuje lepsze rozdzielanie instancji i dokładność szczegółów w niejednoznacznych regionach.
\ Rys. 14 i Rys. 15 ilustrują wydajność naszego modelu i poprzednich prac w ekstremalnych przypadkach z wieloma instancjami. Podczas gdy MGM⋆ ma problemy z szumem i dokładnością w scenariuszach gęstych instancji, nasz model utrzymuje wysoką precyzję. InstMatt, bez dodatkowych danych treningowych, wykazuje ograniczenia w tych złożonych ustawieniach.
\ Solidność naszego podejścia opartego na prowadzeniu maską jest dodatkowo zademonstrowana na Rys. 16. Tutaj podkreślamy wyzwania, z jakimi borykają się warianty MGM i SparseMat w przewidywaniu brakujących części w danych wejściowych maski, którym nasz model przeciwdziała. Jednak ważne jest, aby zauważyć, że nasz model nie jest zaprojektowany jako sieć segmentacji instancji ludzkich. Jak pokazano na Rys. 17, nasze ramy przestrzegają wejściowego prowadzenia, zapewniając precyzyjną prognozę alpha matte nawet z wieloma instancjami w tej samej masce.
\ Wreszcie, Rys. 12 i Rys. 11 podkreślają możliwości generalizacji naszego modelu. Model dokładnie wyodrębnia zarówno ludzkie obiekty, jak i inne przedmioty z tła, demonstrując swoją wszechstronność w różnych scenariuszach i typach obiektów.
\ Wszystkie przykłady to obrazy internetowe bez ground-truth, a maska z r101fpn400e jest używana jako prowadzenie.
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\
:::info Autorzy:
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
:::
:::info Ten artykuł jest dostępny na arxiv na licencji CC by 4.0 Deed (Attribution 4.0 International).
:::
\


Możesz także polubić
![[OPINION] Wraz z ucieczką Bato dela Rosy senatorzy ryzykują otrzymaniem własnych nakazów aresztowania](https://www.rappler.com/tachyon/2026/05/ronald-bato-dela-rosa-senate-plenary-may-12-2026-004-scaled.jpg?resize=75%2C75&crop=538px%2C0px%2C1707px%2C1707px)
[OPINION] Wraz z ucieczką Bato dela Rosy senatorzy ryzykują otrzymaniem własnych nakazów aresztowania

Zniesmaczony pisarz NY Times wskazuje na „rażącą" ironię w sądzie obalającym „szczytowy moment" Ameryki




