

Zcash (ZEC) Hits A ‘Tipping Point,’ Says Electric Coin Co. CEO
Electric Coin Co. (ECC) chief executive Josh Swihart says Zcash has crossed a psychological and developmental threshold after a week of outsized price action and unusually dense ecosystem activity around Token2049 and adjacent events in Singapore. In a long post on X, Swihart characterized the moment as an inflection driven by fundamentals, the macro “zeitgeist,” amplification by key opinion leaders, and the memetic spread that often accompanies crypto upswings.
“Zcash saw a ‘god candle’ this week… The token price and market cap have seen rises in the past, but this time, it really is different. We reached a tipping point,” he wrote. When asked repeatedly “Why now?”, Swihart added with some caution: “The truth is that ‘I can’t say for sure.’ Perhaps it’s as simple as ‘Zcash’s time has come.’ But maybe it’s because the elements that spark and fuel the spread of a movement were finally in place.”
Why Has Zcash Printed A ‘Godcandle’ Last Week?
Swihart anchored his argument in first principles and recent shipping cadence. “Simply, Zcash is the most ideologically and technologically sound form of private money,” he said, pointing to zero-knowledge cryptography, a protocol and community that have “galvanized and matured through many difficult years,” and, crucially, a new layer of usability arriving over the past 12–18 months.
In his view, Zashi—ECC’s consumer wallet—has been a material unlock, especially once paired with Keystone hardware-wallet support for cold storage, NEAR Intents for swapping and spending ZEC, Flexa point-of-sale integrations, and a scaling path “to billions with Tachyon,” a roadmap Swihart credited to engineer Daira Hopwood (@ebfull).
He directed readers to recent theses that predated this week’s move—“Why Zcash Now” (Arjun Khemani), “My Zcash investment thesis” (Frank Braun), and “The case for a small allocation to ZEC” (S. Saint-Léger)—as evidence that fundamentals had been coalescing even before markets noticed.
The “environment,” he argued, is doing the rest. Swihart sketched a stark backdrop of political polarization, censorship creep, and pervasive surveillance—from street cameras to proposed client-side scanning and digital ID programs—contending that this climate naturally elevates private, bearer-style money. “Many are now waking up and realizing that we need tools to protect our liberties… As decentralized private money, Zcash provides shelter from this storm,” he wrote. The macro narrative, in other words, is meeting an asset designed around privacy as a civil-liberties primitive.
Amplification, in Swihart’s telling, has come from a mix of public voices and behind-the-scenes connectors. He credited months of “regular” Zcash commentary from Helius CEO Mert Mumtaz (@0xMert_), new engagement from investor Naval Ravikant (@naval), long-standing advocacy from Balaji Srinivasan (@balajis), and support from builders and investors in adjacent ecosystems, naming @_TomHoward, @akshaybd, @chronear, @juanaxyz00, and @TheVladCostea. “These leaders are the spark that ignited the fire,” he wrote, adding that broader crypto influencers—@gainzy222, @Cryptopathic, @cobie—“have been buzzing.”
Memes, inevitably, are doing distribution. Swihart cited older Zcash slogans—“1 ZEC = 7 BTC,” “ZODL,” “Privacy is Normal”—and newer ones circulating this week, including “encrypted bitcoin,” “$1k ZEC,” and “$50k ZEC,” alongside the rise of @genzcash as a “memetic warfare division” pumping out short-form video.
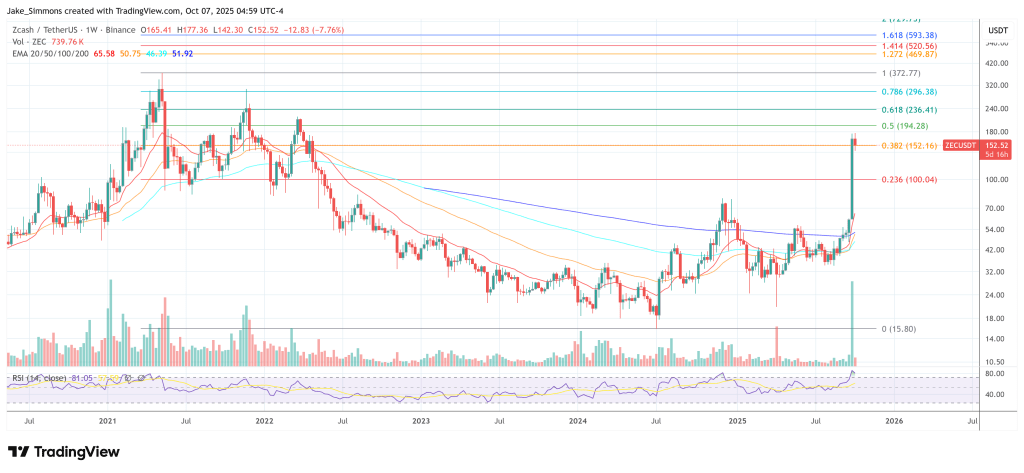
He also leaned into Zcash lore—Edward Snowden’s involvement in a past ceremony, Zooko Wilcox’s early-days connections to Hal Finney and Satoshi—arguing that narrative capital is unusually deep for ZEC. Even the chart, he suggested, has become memetic: “ZEC recently broke above long-standing trends against both fiat and BTC.”
Zcash Is Evolving
Beneath the narrative, Swihart published a tranche of concrete product metrics and core-protocol milestones that help explain his confidence. Zashi’s swap and payments flow since late August totaled “over $9.5 million in ZEC (at $163/ZEC),” with average daily throughput of “1,509 ZEC” and “just under $1M” swapped into ZEC this past week.
Distribution data show “12.1k” unique iOS installs (14.4k total downloads, “4.9*” rating) and an Android install base of “4.83k” (24.2k total including open beta, “4.347*” Play rating). On the protocol side, ECC “finished ZIP 48 transparent multisig support in the Rust crates,” added the same support to zcash-devtool, “ran the Key Holder Organization ceremony for NU 6.1 mainnet,” “set NU 6.1 mainnet consensus rules,” and “released zcashd 6.10.0” along with supporting Rust crates. Mobile SDK FFI changes to accommodate Zashi’s new features also landed this week.
The near-term roadmap focuses on removing friction in everyday use and on-ramp flows without diluting privacy guarantees. Swihart flagged “rotating ephemeral transparent addresses for one-time use cases (swaps, Coinbase onramp),” the ability to “mark received transactions as trusted to reduce the number of confirmations required before spending,” and a draft ZIP for key rotation covering “ZSA issuance keys & lockbox FROST multisig disbursement keys” targeted at NU7.
He also noted review work on QEDit’s ZSA pull requests to the Orchard crate. On the wallet side, forthcoming Zashi features include “ephemeral, transparent addresses for all NEAR-intent-supported functionalities,” “Marking a Transaction as Trusted,” and continued debugging and design finalization for “Transparent Address Rotation, support for Ledger Hardware Wallet, Duress/Decoy Wallet feature, Multi-Account Support, [and] Reset Zashi revamp & home buttons personalization.”
The week’s activity extended beyond GitHub. Swihart said he and long-time Zcash engineer Str4d “spent the week in Singapore in various meetings around Token 2049 and the Network State in support of Zcash, Zashi, Tachyon, and Cross Link with the Shielded Labs team.” He and Zooko also spoke at the Network State Conference, with a recording available, and community organizers held a Zcash day at the Network School featuring a roundtable with Balaji Srinivasan.
The cumulative effect, in Swihart’s reading, is a feedback loop between shipping, discourse, and market structure: “fuel + environment + spark + spread = tipping point.”
At press time, ZEC traded at $152.
Ayrıca Şunları da Beğenebilirsiniz

South Korea Launches Innovative Stablecoin Initiative

Trump Cancels Tech, AI Trade Negotiations With The UK
